프로모션 기간이나 이벤트 기간에 유저가 폭발적으로 늘어난다면? 어떻게 처리할것인가?
이런 질문을 받는다면 어떻게 접근할 것인가?
- DB I/O 를 줄이기 위해 캐시?
- JPA 쿼리 최적화??
이렇게만 접근했다면 Spring MVC + RDBMS 개발에만 너무 한정되어 있었다고 생각한다. ( 내 얘기이다... )
물론 해당 방법으로 접근해도 개선이 되는것은 맞다.
Blocking I/O

우리가 가장 일반적으로 프로그래밍하는 모델이다. Application에서 I/O 요청을 하고 끝날때까지 Block 되어 다른 작업을 수행할 수 없다.
하지만 Spring Web Application 개발을 하면 Tomcat이나 Netty가 Multi Thread 기반으로 동작하기 때문에 Block 안된듯이 동작한다. 이렇게 되면 여러 개의 I/O를 처리하려면 여러 개의 Thread를 사용해야 하는데 이는 매우 비효율적이다.
Blocking I/O를 좀더 개선하자! Synchronous Non-Blocking I/O
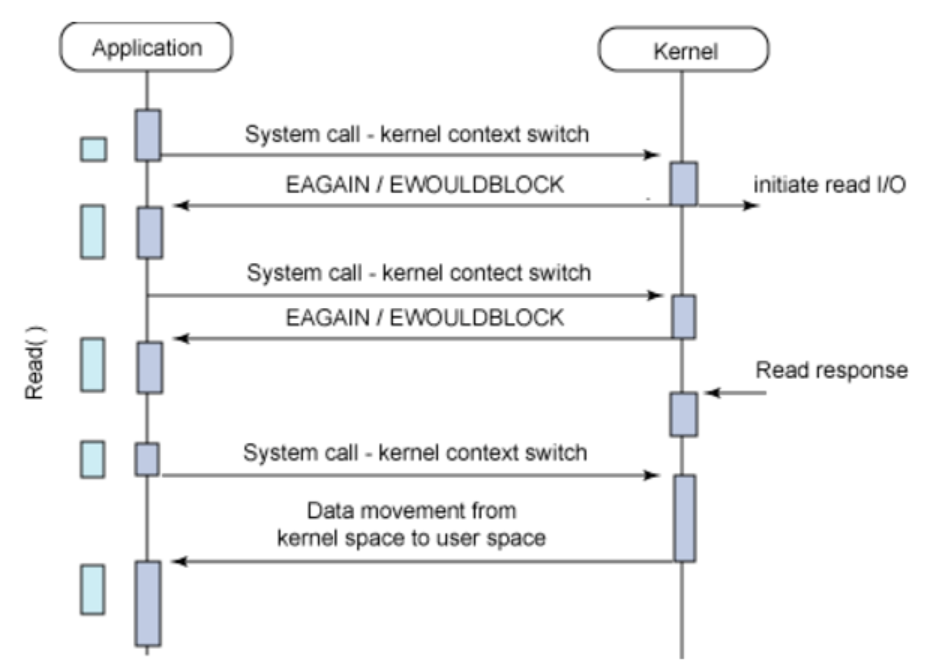
Application에서 I/O를 요청 후 바로 return되어 다른 작업을 수행하다가 주기적으로 데이터가 다 준비 되었는지 확인을 한다. 결국 데이터의 준비가 끝나면 종료된다. 이렇게 체크하는 방식을 폴링(polling) 이라 한다. 결국 이 또한 작업이 끝날때까지 주기적으로 호출하기 때문에 불필요하게 자원을 사용하게 된다.
Thread 좀더 소중하게 쓰고 싶어! - Asynchronous Non-blocking I/O
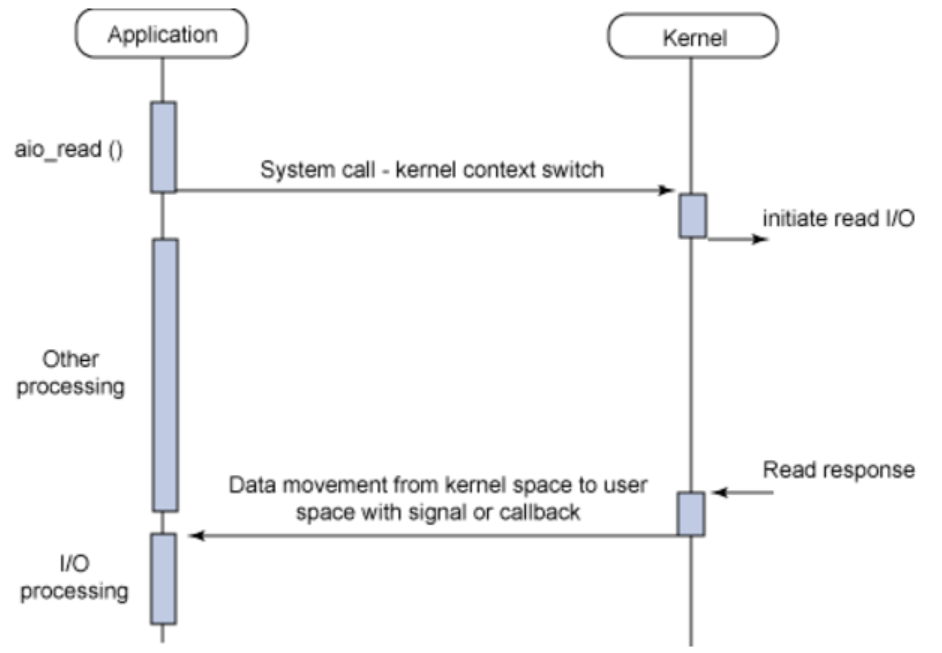
I/O 요청을 한후 즉시 리턴된다. polling 방식과 다르게 데이터 준비가 진짜 끝났을 때 callback 을 통해 알려준다. 이전 방식 보다 좀더 효율적이긴하다!
자바 코드로 살펴보면, 3초 걸리는 API를 3번 호출시 Blocking I/O는 9초, Non Blocking I/O는 3초 정도 걸린다. 훨씬 효율적이긴 하지만, 그만큼의 Thread 생성으로 인하여 Context Switching 오버헤드가 존재한다!!
@Test
public void nonBlocking3() throws InterruptedException {
final StopWatch stopWatch = new StopWatch();
stopWatch.start();
for (int i = 0; i < LOOP_COUNT; i++) {
this.webClient
.get()
.uri(THREE_SECOND_URL)
.retrieve()
.bodyToMono(String.class)
.subscribe(it -> {
count.countDown();
System.out.println(it);
});
}
count.await(10, TimeUnit.SECONDS);
stopWatch.stop();
System.out.println(stopWatch.getTotalTimeSeconds());
}Context Switching 오버헤드도 해결하자! - Event Driven
Spring Framework 에서 Blocking I/O -> Non Blocking I/O 해결 과정
아래 그림에서 왼쪽은 non-blocking I/O를 이용해서 많은 양의 동시성 연결을 다룰 수 있는 Reactive Stack이고, 오른쪽은 blocking 방식의 Servlet Stack이다.


Spring MVC
아래 그림처럼 클라이언트로부터 요청이 들어오면 Queue를 통하게 된다. 스프링 어플리케이션은 요청당 Thread 한개가 할당된다. ( One Request Per Thread Model ) 즉, Thread Pool이 수용할 수 있는 요청까지만 동시적으로 작업이 처리되고 만약 넘게 된다면 큐에서 대기하게 된다.
Thread 생성 비용은 크기 때문에 미리 생성하여 재사용함으로써 효율적으로 사용한다. 서버 성능에 맞게 Thread 최대 수치를 제한 시키는데, tomcat 기본 사이즈는 200이다.

즉, thread pool size 200을 지속적으로 초과하게 된다면, Queue에서 계속 대기하게 된다. 전체 대기시간이 늘어나게 되는데 이런 현상을 Thread Pool Hell 이라 한다. 아래 그림은 링크드인의 Thread pool hell 현상에 대한 그래프이다. Thread pool 감당 사이즈를 넘는 요청이 들어오는 순간부터 수배나 많은 지연시간을 보여준다.

하나의 작업이 늦게 처리되는 부분은 DB, Network 등의 I/O가 일어나는 부분에서 많은 시간이 소비된다. I/O작업은 CPU가 관여하지 않는다. I/O를 가장 효율적으로 처리할 수 있는 방식이 Spring에서 제공해주는 WebFlux이다.
Spring WebFlux
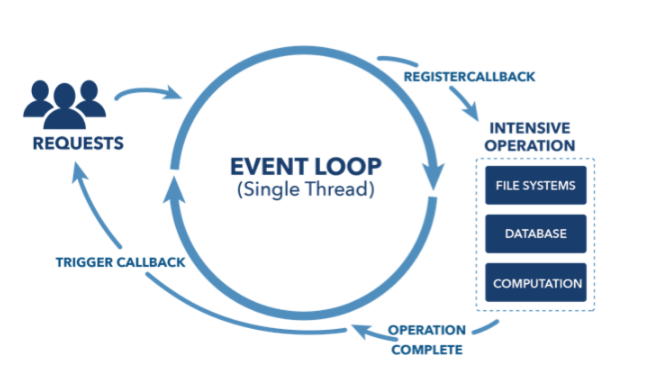
위 그림은 WebFlux 구조에 대한 그림이다. 요청별로 Thread를 생성하는 것이 아니라, 다수의 요청을 적은 Thread로 처리를 한다. Worker Thread 기본 사이즈는 서버의 Core 개수로 설정이 되어있다. 즉 core 수가 4개라면 4개의 Thread로 대용량 트래픽을 감당한다는 것인가? ( Node.js에서 본 아키텍처이다... )
이렇게 Non Blocking 방식을 활용하면 효율적인 I/O 제어가 되어 성능이 향상될 수 있다. 그래서 MSA에서 네트워크 호출이 많기 때문에 적용하기 좋다. 하지만!! I/O 작업 중 하나라도 Blocking 방식이 있다면, 결국 Blocking이 발생되기 때문에 4개의 Thread 이후 요청은 결국 대기를 해야한다.
위와 관련된 예가 DB connection 일 것이다. 아무 생각없이 blocking 되는 DB connection을 넣어놓고 나머지는 non-blocking 방식으로 구현했다면 문제가 발생한다. MongoDB, Redis 등의 NoSQL은 non-blocking db connection을 지원한다고 한다!
와 그러면 무조건 WebFlux로 성능도 챙기고, 개발도 멋있게 하자?
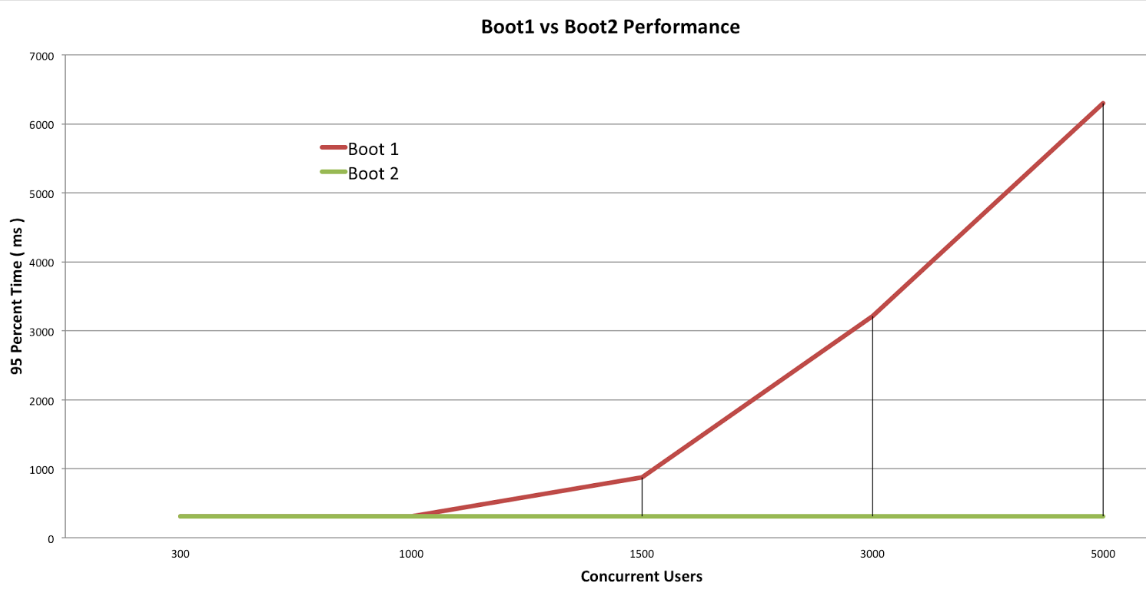
해당 그림을 보면 Spring MVC와 Spring WebFlux 성능이 비슷한 구간이 있다. 서버의 성능이 좋아진다면 비슷한 구간이 더 늘어날 것이다.
Spring Document에서 조차도 동기 방식이 코드 작성, 이해, 디버깅 하기가 좋다고 한다. ( 나만 그런게 아니였어... ) 결국 생산성 측면에서는 동기 방식 코딩이 훨씬 높기 때문에 서비스 규모나 서버의 성능에 따라 잘 따져보아야 한다.
왜 성능이 동일한 구간이 생길까?
위의 그림에서 Concurrent Users가 1000명 이하일때는 Thread Pool이 감당할 수 있는 정도의 요청이었기 때문이다. 이후에는 Queue에 쌓여 점점 성능이 느려진것이다.
WebFlux 간단한 예제 코드
@SpringBootApplication
@EnableWebFlux
public class ExampleApplication {
@Bean
HelloHandler helloHandler() {
return new HelloHandler();
}
@Bean
RouterFunction<ServerResponse> helloRouterFunction(HelloHandler helloHandler) {
return RouterFunctions.route(RequestPredicates.path("/"), helloHandler::handleRequest);
}
public static void main(String[] args) throws Exception {
SpringApplication.run(ExampleApplication.class);
}
}
public class HelloHandler {
public Mono<ServerResponse> handleRequest(ServerRequest serverRequest) {
return ServerResponse.ok().body(Mono.just("Hello World!"), String.class);
}
}
참고 ( 감사합니다 ! )