현업에서 주문, 결제 등등 민감한 데이터를 수정하는 경우 항상 트랜잭션과 관련된 내용이 나온다. 락은 자원을 선점하도록 설계하지 말고 보통 기본으로 사용하다가 문제가 발생하면 그때 대응하는 식으로 개발했다. ( 대용량 트래픽의 회사에서 근무하시거나 제가 잘못된 개발 방법이라면 언제든 댓글 달아주세요 )
트랜잭션과 격리수준
- 원자성(Atomicity) : 트랜잭션 내에서 실행된 작업들은 마치 하나의 작업처럼 모두 성공하거나 모두 실패해야 한다
- 일관성(Consistency) : 데이터베이스에서 정한 무결성 제약조건을 항상 만족해야 한다
- 격리성(Isolation) : 동시에 실행되는 트랜잭션들이 서로에게 영향을 미치지 않도록 격리한다. 예를 들어, 동시에 데이터를 수정하지 못하도록 한다. 하지만, 격리성은 동시성과 관련된 성능 이슈로 인해 격리 수준을 선택해야 한다. 이와 관련되서는 뒤에서 살펴보자.
- 지속성(Durability) : 트랜잭션을 성공적으로 끝내면 그 결과가 항상 기록되어야 한다.
트랜잭션은 원자성,일관성,지속성은 보장한다. 격리성은 완벽히 보장하지 않기 때문에 완벽히 보장하려면 차례대로 실행해야 한다. 이렇게 되면 동시성 처리 성능이 상당히 나빠지기 때문에 ANSI 표준이 4가지 격리수준을 정의 해 주었다.
- READ UNCOMMITED
- READ COMMITED : 다른 사용자가 데이터를 변경하는 동안 사용자는 데이터를 읽을 수 없다.
- REPEATABLE READ : 선행 데이터가 조회한 데이터는 트랜잭션이 종료될때까지 후행 트랜잭션잉 수정 삭제가 불가능
- SERIALIZABLE : 동일한 데이터에 대해서 두개의 트랜잭션이 수행 될 수 없다.
| 격리 수준 | DIRTY READ | NON-REPEATABLE READ | PHANTOM READ |
| READ UNCOMMITED | v | v | v |
| READ COMMITED | v | v | |
| REPEATABLE READ | v | ||
| SERIALIZABLE |
Dirty READ
커밋하지 않은 데이터를 읽을 수 있을 때 발생하는 문제다. 트랜잭션 1가 데이터를 수정하고 있는데 트랜잭션 2가 이 데이터를 읽어올 수 있다. 하지만, 트랜잭션 1에서 롤백을 하면 트랜잭션 2는 잘못된 데이터를 읽고 있게 된다. 즉, 데이터 정합성에 심각한 문제가 발생한다. DIRTY READ를 허용하는 격리 수준을 READ UNCOMMITED라 한다.
Non repeatable READ
커밋한 데이터만을 읽을 수 있을 때 발생하는 문제다. dirty read는 발생하지 않는다. 하지만, 트랜잭션 1에서 회원 A를 조회를 2번 하는데 트랜잭션 2에서 중간에 회원 A를 수정한 경우, 한번은 원래 데이터가 한번은 수정된 데이터가 조회된다. 이처럼 반복해서 같은 데이터를 읽을 수 없는 상태를 non repeatable read라 한다. read commited 격리수준에서 이를 허용한다.

PHANTOM READ
한 번 조회한 데이터를 반복 조회해도 같은 데이터가 조회된다. 하지만, 트랜잭션 1이 20살 이상의 회원을 조회했는데 트랜잭션 2가 25살 회원을 추가한 경우, 트랜잭션 1은 다른 상태로 회원들을 조회하게 된다. 이처럼 반복 조회시 결과 집합이 달라지는 것을 phantom read라 한다. 이를 허용하는 격리 수준이 repeatable read이다.

애플리케이션은 대부분 동시성 처리가 중요하므로 보통 read commited 격리 수준을 기본으로 사용한다.
스프링에서는 아래와 같이 @Transactional 어노테이션에 isolation level을 설정할 수 있다.
@Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRED, rollbackFor = Exception.class)
public int method(int i) throws Exception {
return sqlMapClient.delete("~~~~");
}
낙관적 락과 비관적 락 기초
JPA의 영속성 컨텍스트(1차 캐시)를 적절히 활용하면 데이터베이스의 격리수준이 READ COMMITED 여도 애플리케이션 레벨에서 반복 가능한 읽기(repeatable read)가 가능하다. 하지만 일부 로직에서 더 높은 격리 수준이 필요하면 낙관적 락과 비관적 락 중 하나를 사용해야 한다.
낙관적 락
애플리케이션이 제공하는 락이다. 즉, 데이터베이스가 제공하는 락 기능을 사용하는 것잉 아니라 JPA가 제공하는 버전 관리 기능을 사용한다. 낙관적 락은 트랜잭션을 커밋하기 전까지는 트랜잭션의 충돌을 알 수 없다는 특징이 있다.
비관적 락
트랜잭션의 충돌이 발생한다고 우선 락을 걸고 보는 방법이다. 데이터베이스에서 제공하는 락 기능을 사용한다. ( ex : select for update 구문 )
second lost updates problem ( 두 번의 갱신 분실 문제 )
데이터베이스 트랜잭션 범위를 넘어서는 문제가 있다. 예를 들어, 사용자 A,B가 상품 이름을 같이 수정하고 같이 확인 버튼을 누른다면? 버튼을 조금 늦게 누른 사람의 상품 이름으로 수정이 될 것이다. 이를 두번의 갱신 분실 문제라고 한다.
3가지 선택 방법이 있다.
- 마지막 커밋만 인정하기 : 마지막에 커밋한 사용자 B의 내용만 인정
- 최초 커밋만 인정하기 : 먼저 수정한 사용자 A의 내용이 수정되고 B는 오류가 발생한다.
- 충돌하는 갱신 내용 병합하기 : A,B의 내용을 병합
최초 커밋만 인정하기 - @Version
@Entity
@Table(name = "orders")
@Getter
@Setter
public class Order {
@Id
@Column(name = "order_id")
private String id;
@Version
private Integer version;
}엔티티를 수정할 때마다 버전이 하나씩 자동으로 증가한다. 그렇기 때문에 다른 쪽에서 먼저 수정을 해버리면 version이 맞지 않아 예외가 발생한다. 즉, 버전 정보를 사용하면 최초 커밋만 인정하게 된다.
JPA에서 버전 정보는 어떻게 비교하는 것일까? 우리가 생각한 단순한 방법 그대로 사용하고 있었다.
UPDATE BOARD
SET
TITLE=?
VERSION=? ( 버전 +1 증가 )
WHERE
ID=?
AND VERSION=? ( 버전 비교 )주의해야 할점은 벌크 연산을 하는 경우에는 버전이 증가하지 않는다. ( JPA가 쿼리를 만들어줄때 생성되는 문구니까.... ) 그렇기 때문에
update Member m set m.name='test', m.version= m.version+1;과 같이 해주어야 한다.
JPA 락 사용
JPA가 제공하는 락을 어떻게 사용하는지 알아보자
JPA를 사용할 때 추천하는 전략은 READ COMMITED 트랜잭션 격리 수준 + 낙관적 버전 관리이다 ( 두 번 갱신 내역 분실 문제 예방)
스프링 JPA에서는 아래와 같이 jpa락을 사용할 수 있다. LockModeType에 어떤 것들이 있는지 알아보자.
public interface AgentRepository extends JpaRepository<Agent, Long> {
@Lock(LockModeType.OPTIMISTIC)
Optional<Agent> findByMember_MemberIdx(long memberIdx);
}스프링 JPA 기본 락 모드는 NONE이다.
NONE
락 옵션을 적용하지 않아도 엔티티에 @Version이 적용된 필드가 있으면 낙관적 락이 적용된다.
- 용도 : 조회한 엔티티를 수정할 때 다른 트랜잭션에 의해 변경되지 않아야 한다.
- 동작 : 엔티티를 수정할 때 버전을 체크하면서 버전을 중가함 ( update 쿼리 상용 )
- 이점 : second lost update problems가 해결된다.
OPTIMISTIC
이 옵션을 사용하면 조회만 해도 버전을 체크한다.
- 용도 : 조회한 엔티티는 트랜잭션이 끝날때까지 다른 트랜잭션에 의해 변경되지 않아야 한다. 조회 시점부터 트랜잭션이 끝날 때까지 조회한 엔티티가 변경되지 않음을 보장함
- 동작 : 트랜잭션을 커밋할 때 버전 정보를 조회해서 ( SELECT 쿼리 사용 ) 현재 엔티티의 버전과 같은지 검증한다. 만약 같지 않으면 예외 발생
- 이점 : DIRTY READ와 NON-REPEATABLE READ를 방지 할 수 있다.
2차 캐시
스프링 마이크로서비스로 개발을 하면 대부분 네트워크를 통해 데이터베이스에 접근을 한다. 영속성 컨텍스트 내부에는 엔티티를 보관하는 1차 캐시 저장소가 있다. 하지만, 클라이언트의 요청이 들어오고 끝날 때 까지만 1차 캐시가 유효하기 때문에, 데이터베이스 접근 횟수를 획기적으로 줄이지는 못한다.
대부분의 JPA 구현체들은 애플리케이션 범위의 캐시를 지원하는데 이것을 공유 캐시 또는 2차 캐시라고 한다. 이제 어플리케이션 조회 성능을 향상할 수 있다.
1차 캐시
스프링 프레임워크 같은 컨테이너 위에서 실행하면 트랜잭션을 시작할 때 영속성 컨텍스트를 생성하고 트랜잭션을 종료할 때 영속성 컨텍스트도 종료한다. 1차 캐시는 끄고 킬 수 있는 옵션이 아니다.

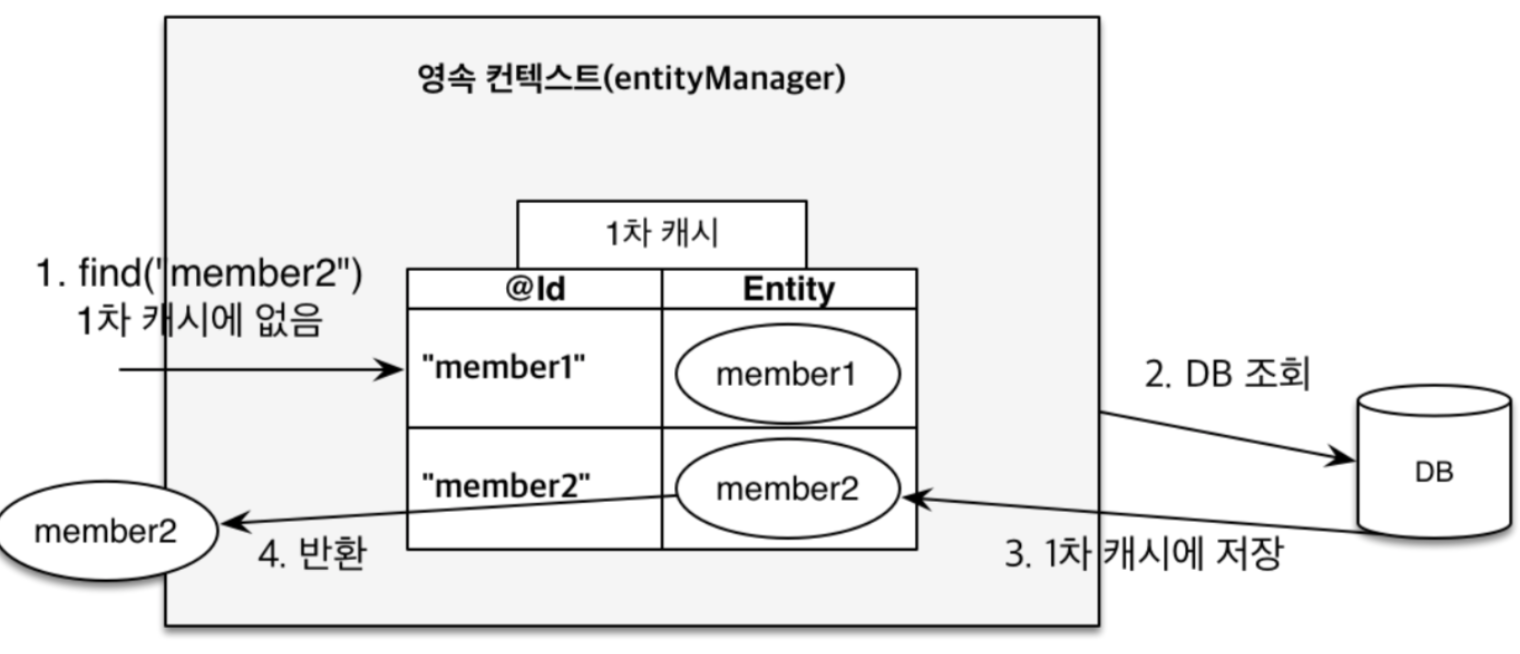
1차 캐시의 특징은 다음과 같다,
- 1차 캐시는 기본적으로 영속성 컨텍스트 범위의 캐시다. ( 컨테이너 환경에서는 트랜잭션 범위의 캐시, OSIV에서는 요청 범위의 캐시 )
- 같은 엔티티가 있으면 해당 엔티티를 그대로 반환한다. 즉, 객체 동일성을 보장한다.
2차 캐시
애플리케이션 단의 캐시로 2차 캐시 ( L2 cache, second level cache )라 부른다. 따라서 애플리케이션이 종료될 때까지 캐시가 유지된다.
2차 캐시의 특징은 다음과 같다
- 동시성을 극대화하기 위해서 캐시한 객체를 직접 반환하지 않고 복사본을 만들어서 반환함. 왜냐하면, 객체를 그대로 반환하면 여러 곳에서 같은 객체를 동시에 수정하는 문제가 발생한다. 이를 해결하려면 객체에 락을 걸어야 하는데 이렇게 하면 동시성이 떨어질 수 밖에 없다. 락에 비하면 객체 복사하는 비용은 아주 저렴하다.

JPA 2차 캐시 기능
JPA 2.0에 와서 캐시 표준을 정의하였다. 캐시 모드를 설정하려면 Entity 객체 위에 @Cacheable을 써주면 된다. 그리고 application.yml에 아레와 같이 설정을 해주면 된다.
spring.jpa.properties.javax.persistence.sharedCache.mode=ENABLE_SELECTIVEcache mode는 아래와 같이 5가지가 있다.
| 캐시 모드 | 설명 |
| ALL | 모든 엔티티를 캐시한다. |
| NONE | 캐시를 사용하지 않음 |
| ENABLE_SELECTIVE | Cacheable(true)로 설정된 엔티티만 캐시를 적용한다. |
| DISABLE_SELECTIVE | 모든 엔티티를 캐시하는데 Cacheable(false)만 캐시하지 않는다 |
| UNSPECIFIED | JPA 구현체가 정의한 설정을 따른다 |
JPA 캐시 관리 API
JPA는 캐시를 관리하기 위해서 javax.persistence.Cache 인터페이스를 제공한다.
Cache cache = emf.getCache();
boolean contains = cache.contains(TestEntity.class, TestEntity.getId());hibernate나 ehcache 적용은 나중에 실제로 구현할 때 다시 정리해야 겠다.
관련 내용 이슈 모음
could not execute statement; SQL [n/a]; nested exception is org.hibernate.exception.LockAcquisitionException: could not execute statement,
'Back-End > JPA' 카테고리의 다른 글
| Spring JPA 다대다 설정 및 성능 주의 ( Many To Many ) (1) | 2019.11.28 |
|---|---|
| Spring JPA의 사실과 오해 - NHN FORWARD (0) | 2019.11.27 |
| 14장. JPA 컬렉션과 부가기능 (0) | 2019.11.12 |
| Spring jpa save(), saveAndFlush() 제대로 알고 쓰기 (2) | 2019.11.12 |
| ObjectOptimisticLockingFailureException (0) | 2019.11.02 |

