Deadlock found when trying to get lock; try restarting transactionDeadlock이 발생하게 된 코드 및 상황
@Transactional(isolation = Isolation.SERIALIZABLE)
override fun save(userNo: Int, productId: Int): Order {
return repository.findByProductId(productId)?.let {
println("[${Thread.currentThread().id}] - $productId count is increased - ${it.count}")
it.count += 1
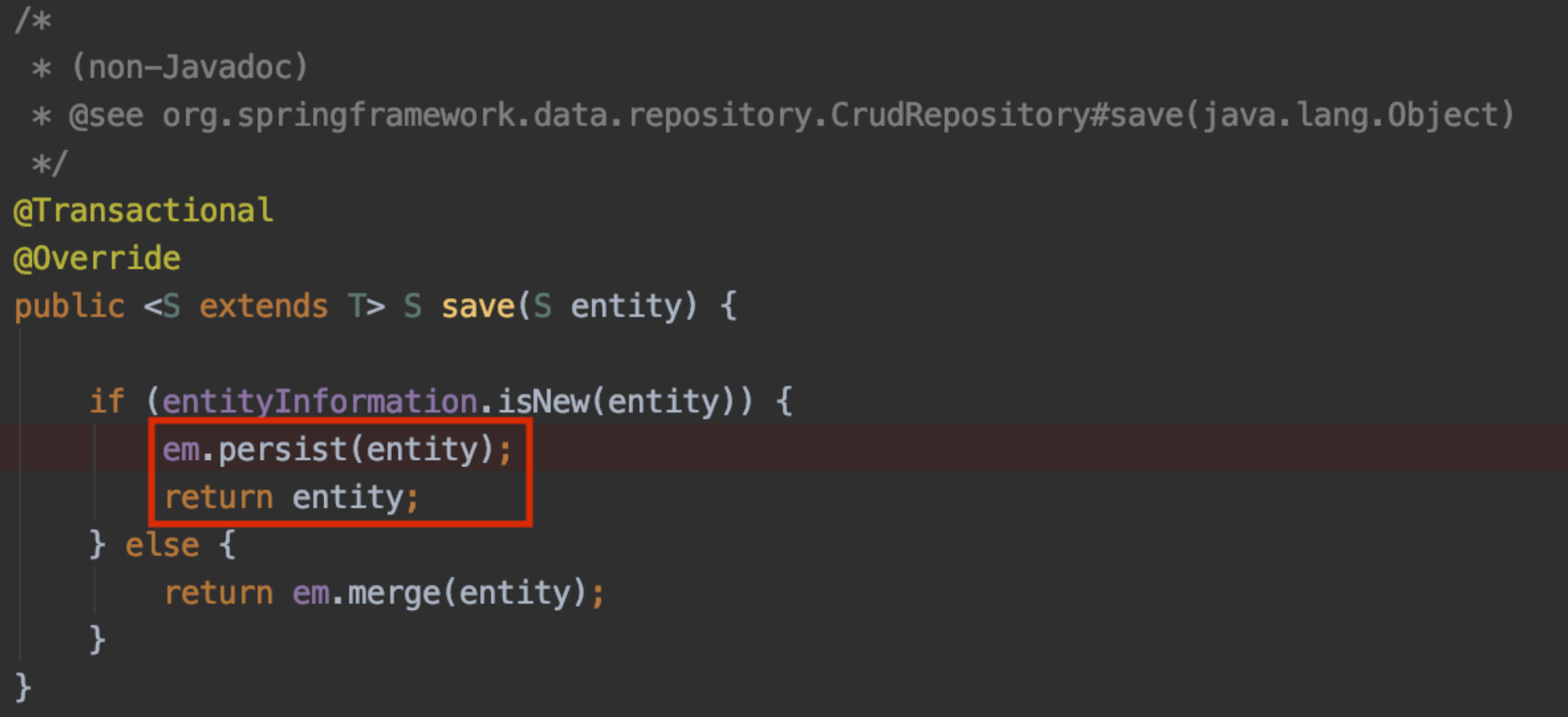
return repository.save(it)
} ?: createOrder(userNo, productId)
}아직 상품이 등록되지 않은 상태에서 추가하는 두 요청이 동시에 온다면?
- 요청1, 요청2가 동시에 같은 row에 Shared Lock 을 잡게 된다.
- 요청1과 요청2가 동시에 write 작업을 할 때 요청1과 요청2는 서로 Shared Lock을 놓아줄 때 까지 기다린다.
- 위와 같은 Deadlock exception 발생
InnoDB에 deadlock detection 설명은 뭐라 나와있을까?
InnoDB는 자동으로 transaction deadlock을 감지하고 deadlock을 풀기 위해 transaction을 롤백한다. InnoDB는 insert,update,delete할 row 수의 크기가 적은 트랜잭션을 롤백하도록 한다. InnoDB가 트랜잭션의 완전한 롤백을 할때, 트랜잭션에 의해 잡힌 모든 락은 풀린다.
InnoDB automatically detects transaction deadlocks and rolls back a transaction or transactions to break the deadlock. InnoDB tries to pick small transactions to roll back, where the size of a transaction is determined by the number of rows inserted, updated, or deleted. When InnoDB performs a complete rollback of a transaction, all locks set by the transaction are released. However, if just a single SQL statement is rolled back as a result of an error, some of the locks set by the statement may be preserved. This happens because InnoDB stores row locks in a format such that it cannot know afterward which lock was set by which statement.
https://dev.mysql.com/doc/refman/5.6/en/innodb-deadlock-detection.html
MySQL :: MySQL 5.6 Reference Manual :: 14.7.5.2 Deadlock Detection and Rollback
14.7.5.2 Deadlock Detection and Rollback InnoDB automatically detects transaction deadlocks and rolls back a transaction or transactions to break the deadlock. InnoDB tries to pick small transactions to roll back, where the size of a transaction is determ
dev.mysql.com
InnoDB에 Locking 설명은 뭐라 나와있을까?
Lock 전략은 동시성과 ACID 간의 균형이 잘 맞아야 한다. Lock 전략을 올바르게 튜닝하는 것은 모든 데이터베이스 동작이 안전하고 신뢰가 있어야 한다. 즉, 동시성을 어느정도는 포기해야 한다...
The system of protecting a transaction from seeing or changing data that is being queried or changed by other transactions. The locking strategy must balance reliability and consistency of database operations (the principles of the ACID philosophy) against the performance needed for good concurrency. Fine-tuning the locking strategy often involves choosing an isolation level and ensuring all your database operations are safe and reliable for that isolation level.
http://dev.mysql.com/doc/refman/5.5/en/glossary.html#glos_locking
어떻게 돌아가는걸까?
@GeneratedValue(strategy=GenerationType.AUTO)
JPA에서 DB Insert 시에 id 생성 방식은 기본이 DB방식을 따르는 것이다.
/**
* Indicates that the persistence provider should pick an
* appropriate strategy for the particular database. The
* <code>AUTO</code> generation strategy may expect a database
* resource to exist, or it may attempt to create one. A vendor
* may provide documentation on how to create such resources
* in the event that it does not support schema generation
* or cannot create the schema resource at runtime.
*/
AUTOMySQL은 Sequence를 지원하지 않기 떄문에 hibernate_sequence라는 테이블에 단일 ROW를 사용하여 ID 값을 생성한다. 여기서 hibernate_sequence 테이블을 조회, update를 하면서 sub transaction이 생기게 된다.
ID 자동생성해서 하나만 주세여~
select next_val as id_val from hibernate_sequence for update;MySQL for update 쿼리는 조회한 row에 lock을 걸어 현재 트랜잭션이 끝나기 전까지 다른 session의 접근을 막는다. Id가 중복되면 안되기 때문에 동시성 제어를 위해 이런 Query가 사용된다.
그리고 별도 sub transaction으로 구성한 이유도 상위 transaction이 끝날 떄까지 다른 thread에서 ID 채번을 할 수 없기 떄문일 것이다.



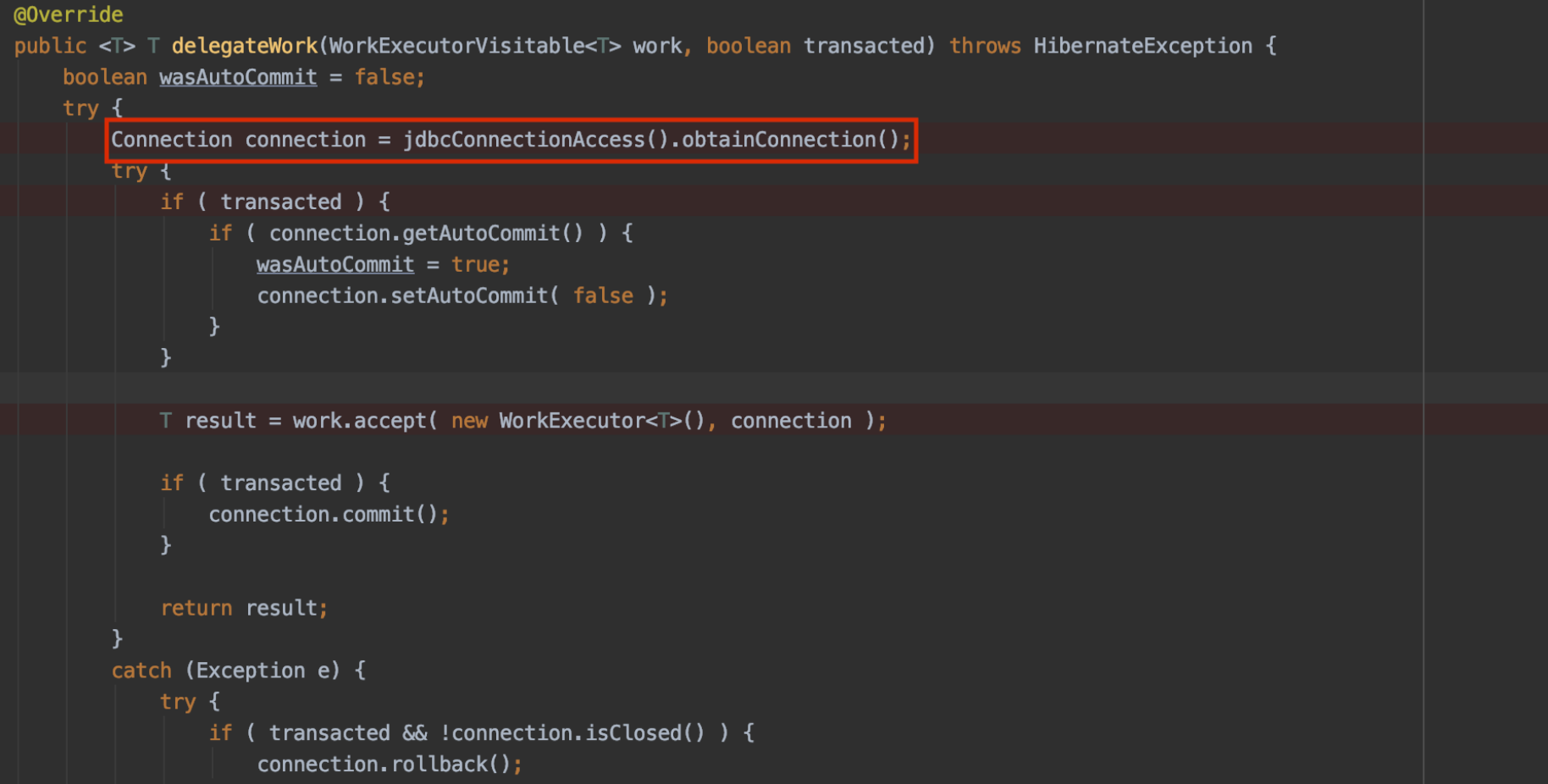
위에 보이는대로 ID 채번을 위해 connection을 획득하고 2번째 connection을 가져오게 됩니다.ID를 조회하고 update하는 transaction이 commit되면 connection이 바로 pool에 반납된다.
해결 방법?
트랜잭션 모델에 더 공부하고 싶다면 아래 링크를 확인하자
https://dev.mysql.com/doc/refman/5.7/en/innodb-transaction-model.html
'Back-End > JPA' 카테고리의 다른 글
| JPA 15장. 고급 주제와 성능 최적화 (0) | 2020.01.23 |
|---|---|
| 1장. JPA 소개 (0) | 2020.01.23 |
| JPA / ORM 개발시 성능 향상시키기 (0) | 2019.12.21 |
| JPA 8장 - 프록시와 연관관계 정리 (0) | 2019.12.11 |
| Spring JPA 이슈 모음 (0) | 2019.12.09 |

