들어가기 전에
나는 아직 실력이 부족한 개발자여서 레디스=캐시 로의 의미로만 이해하고 있었다. 대부분의 서비스에서 단순 캐시용도로만 사용하기도 한다. 레디스에 대해 정확히 이해를 하지 않으면 성능이 제대로 나오지 않을 수도 있고, 제대로 활용하지도 못할 수도 있다.
- 레디스를 어떻게 배치할까?
- 캐싱 전략?
- 단순 캐시용도말고 다른 용도로는 어떻게 쓸까?
그래서 나의 부족한 지식을 채우기 위해 해당 포스팅을 작성하게 되었다.

캐싱 전략 - Look Aside ( = Lazy Loading )
캐시를 옆에 두고 필요할 때만 데이터를 캐시에 로드하는 전략이다. ( key-value 형태로 저장됨 )
- 데이터 가져오는 요청
- Redis에 먼저 요청 -> 있으면 반환
- 없으면 데이터베이스에 데이터 요청
- 이 데이터를 레디스에 저장

이 구조는 실제로 사용되는 데이터만 캐시에 저장되고, 레디스의 장애가 어플리케이션에 치명적인 영향을 주지 않는 장점이 있다.
하지만 아래와 같은 단점도 있다.
- 캐시에 없는 데이터인 경우 더 오랜 시간이 걸림
- 캐시가 최신 데이터를 가지고 있는가? ( 데이터베이스에 데이터가 업데이트 된다고 레디스가 업데이트 되는건 아님 )
Write-through
Wirte-through 구조는 데이터를 데이터베이스에 작성할 때마다 캐시에 데이터를 추가하거나 업데이트한다. 이로 인해 캐시의 데이터는 항상 최신 상태로 유지할 수 있지만,
- 쓰지 않는 데이터도 캐시에 저장되기 때문에 리소스 낭비
- 쓰기 지연 시간 증가
와 같은 단점도 발생한다.
이를 해결하기 위해, TTL(Time-to-live)을 꼭 사용하여 사용되지 않는 데이터를 삭제해야 한다.

레디스 활용 사례
사례 1 - 좋아요 처리하기
좋아요 처리에서 가장 중요한 것은 한 사용자가 하나의 댓글에 좋아요를 한번씩만 할수 있다는 것이다.
RDBMS에서 유니크 조건을 걸어서 구현할 수 있지만, 이렇게 insert와 update가 자주 발생하는 경우 RDBMS 성능 저하가 필연적으로 발생하게 된다.
레디스의 Set을 이용하면 간단하게 구현할 수 있으며, 빠른 시간 안에 처리할 수 있다.
댓글의 번호를 key로 하고, 해당 댓글에 좋아요를 누른 회원 ID를 아이템으로 추가하면 위의 조건을 만족할 수 있다.
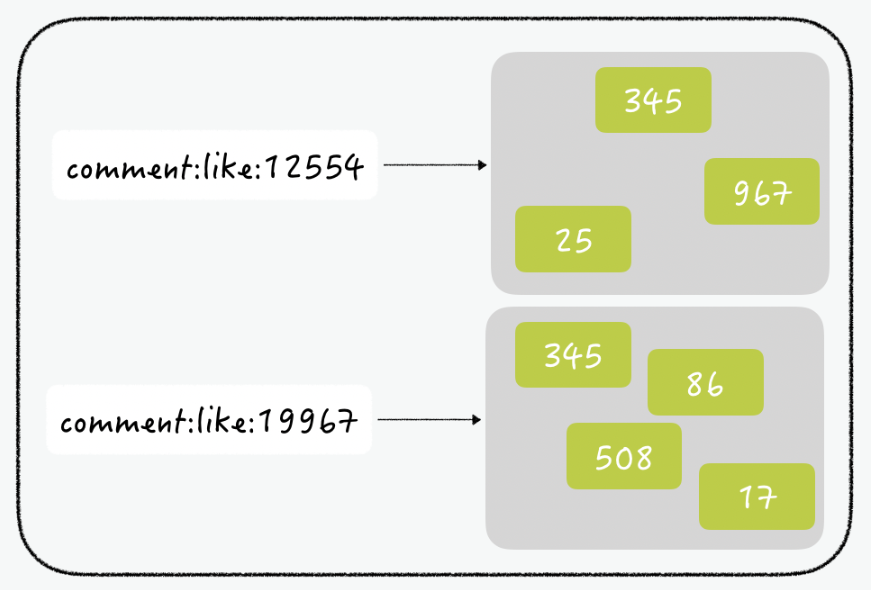
제디스를 이용하여 구현을 하면 초당 약 16만건의 커맨드를 처리할 수 있다고 한다.
사례 2 - 게임 서비스에서 일일 순 방문자수(Unique Visitor) 구하기
순 방문자수는 서비스에 사용자가 하루에 여러번 방문했더라도 한번만 카운팅되는 값이다. ( 중복 제거 )
이를 구현하기 위해서는 아래와 같은 방법이 있다.
- Google Analytics와 같은 외부 서비스 이용
- access log 분석
- 접속 정보를 로그파일로 작성하여 배치 프로그램 작성
밑에 두가지 방법은 실시간으로 데이터를 조회할 수 없다는 단점이 있다.
레디스의 비트 연산을 활용하면 간단하게 실시간 순 방문자를 저장하고 조회하는 방법을 구현할 수 있다.
사용자 ID( ex: 7 )인 비트를 1로 바꾸면, 나중에 문자열에서 1로 설정된 bit의 개수를 구하는 BITCOUNT 연산을 통해 UV를 빠르게 구할 수 있다.

회원이 천만명이라면 가능한가?
천만개의 bit는 1.2MB 정도의 크기이며, 레디스의 string 최대 길이는 512MB이므로 나타내기에는 충분하다.
사례 3 - 출석 이벤트 구현하기
사례 2번을 응용해서 정해진 기간동안 매일 방문한 사용자를 구하는 서비스를 구현한다면?
사례 2번을 이용하여 매일 방문자를 구현하였고,
구해놓은 string 간의 비트를 비교하는 BITOP 커맨드를 사용하면 이 서비스를 구현할 수 있다.

AND 연산을 통해 7번과 11번 사용자가 매일 방문한 것임을 알 수 있다.
사례 4 - 최근 검색 목록 표시하기
최근 검색 목록을 구현한다면? RDBMS 지식만 있는 나였다면
select * from KEYWORD where ID = 123 order by reg_date desc limit 5;이렇게 쿼리를 이용하면 아래와 같은 문제점이 발생한다.
- 중복 제거 관리 필요
- 멤버별로 저장된 데이터의 개수 확인 필요
- 오래된 검색어는 삭제하는 작업
따라서 애초에 중복이 되지 않고, 정렬되어 있는 레디스의 sorted set 을 사용하면 간단하게 구현할 수 있다.
Score는 검색한 나노시간을 나타내고, Member Id는 123을 검색한 멤버의 ID이다.
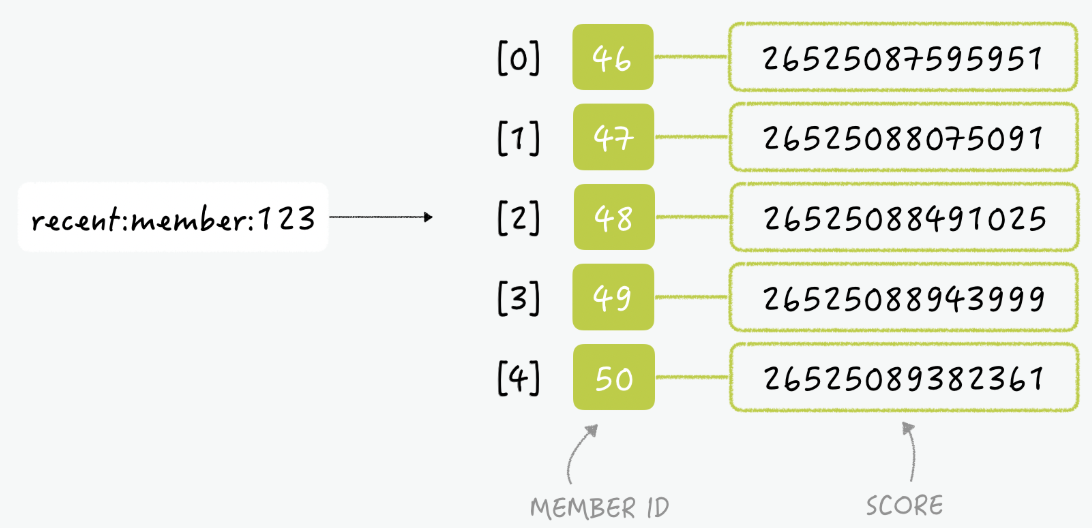
그렇다면 아래와 같이 Member ID가 51인 사람이 Member ID 123인 사람을 검색했다면? 이렇게 마지막에 추가가 된다. 이제 0번은 필요가 없어졌으니 삭제를 해야하는데 뭔가 확인을 하고해야하는 번거러움이 발생한다.
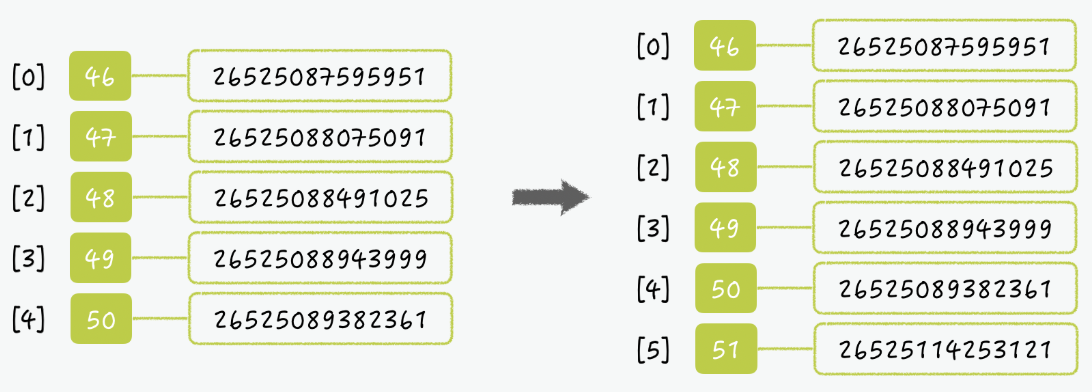
이를 위해서 sorted set의 음수 인덱스를 사용하면 더 간단해진다.
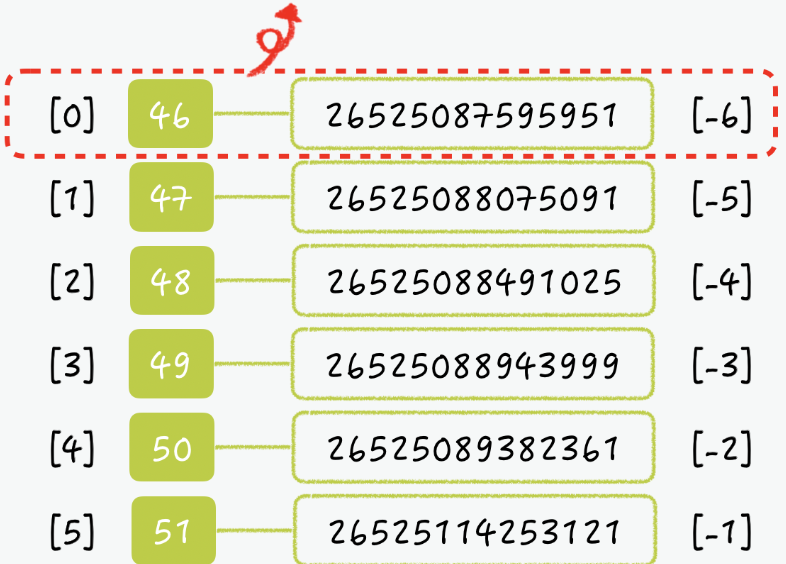
> ZREMRANGEBYRANK recent:member:123 -6 -6데이터에 멤버를 추가한 뒤, 항상 -6번째 아이템을 지운다면 특정 개수 이상의 데이터가 저장되는 것을 방지할 수 있게 된다.
참고
'Back-End > Redis' 카테고리의 다른 글
| 레디스와 분산락 (0) | 2020.07.19 |
|---|---|
| Redis란? (0) | 2020.03.17 |
| Redis Spring Boot에 설정하기 및 개요 (0) | 2020.01.24 |
