데이터 중심 애플리케이션 설계 책을 읽게 된 계기
나는 아직 수백만명의 유저를 지닌 회사에서 일한 경험이 없다. 그렇기 때문에
- 수백만명의 사용자를 감당할 수 있는 데이터 시스템을 어떻게 만들어야 하는가?
- 애플리케이션이 고가용성을 갖추기 위해서는 어떻게 설계해야 하는가?
에 관한 지식이 없었고 이 책을 선택하게 되었다
데이터 중심 어플리케이션에서 공통으로 들어가는 요소들
- 데이터를 저장할 데이터베이스
- 읽기 속도 향상을 위한 값비싼 수행 결과를 기억하는 캐시
- 사용자가 키워드로 데이터를 검색하거나 다양한 방법으로 필터링할 수 있게 제공 ( 검색 색인 - search index )
- 비동기 처리를 위해 다른 프로세스로 메시지 보내는 스트림 처리 ( stream processing )
- 주기적으로 대량의 누적된 데이터를 분석할 일괄 처리 ( batch processing )
데이터 시스템에 대한 생각
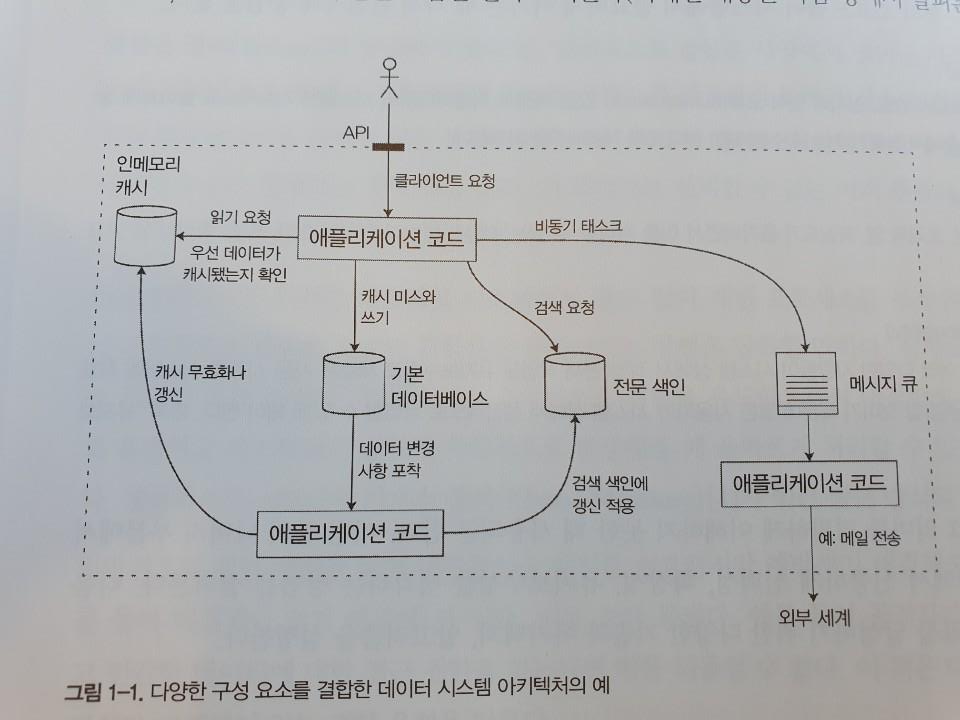
이렇게 위의 구조로 개발을 하다보면 애플리케이션 개발자뿐만 아니라 데이터 시스템 설계의 역할도 맡게 된다. 이때 좋은 설계를 위해서 어떤 부분에 관심을 둬야 할 것인가?
- 신뢰성(reliability) : 하드웨어, 소프트웨어 결합, 인적 오류가 있어도 지속적으로 올바르게 동작해야 함
- 확장성(scability) : 시스템의 데이터 양, 트래픽 양, 복잡도가 증가하면서 이를 처리할 수 있는 적절한 방법
- 유지보수성(maintainability) : 모든 사용자가 시스템 상에서 생산적으로 작업할 수 있게 해야 한다
이 3가지 목표를 달성하기 위한 다양한 기술, 아키텍처, 알고리즘에 대해 알아보자
1. 신뢰성
2. 확장성
성능 저하를 유발하는 이유 중 하나는 부하 증가이다. 확장성은 된다/안된다 이렇게 일차원적인 것이 아니다. 시스템이 특정 방식으로 커질 때 이에 대처하기 위한 선택을 해나가면서 상황에 따라 대처해나가는 것이다
부하 기술하기 - Twitter에서 트윗 작성 / 홈 타임라인 기능을 어떻게 구현했을까?


- 게시된 트윗의 평균 속도 <<< 홈 타임라인 읽기 속도 ( 100배 차이 ) 이기 떄문에 방식 2가 더 잘 동작한다
( 쓰기 시점에 더 많은 일을 하고, 읽기 시점에 적은 일을 한다 ) - 방식 2의 단점 : 더 많은 부가 작업 ( 초당 4.6k 트윗이 작성되고, 초당 345k의 쓰기가 발생하므로 75만명 팔로우에게 전달 된다 )
-> 적시에 트윗을 전송하는 작업이 도전 과제 - 방식 1의 장점 : 유명인인 경우 팔로워 수가 많기 때문에 접근 방식 1처럼 읽는 시점에 사용자의 홈 타임라인에 합치는게 더 좋다.
- 결론 : 트윗은 hybrid 구조로 방식1+방식2를 가져가고 있다
트위터처럼 부하를 결정할 때 팔로우 수처럼 핵심 부하 매개변수에 따라 구조를 다르게 가져갈 수 있다
성능 기술하기
3. 유지 보수성
발전성 - 변화를 쉽게 만들기
아까 트위터에서 방식1 -> 방식 2로 전환할 때 빠르게 대응할 수 있는 방법은 기존 시스템의 간단함과 추상화와 관련되어 있다.
'데이터' 카테고리의 다른 글
| 데이터 중심 어플리케이션 설계 7장-트랜잭션 (0) | 2023.05.21 |
|---|---|
| BigQuery-(1)빅쿼리란 (0) | 2021.12.10 |
| 7장. 트랜잭션 ( 데이터 중심 애플리케이션 설계 ) (0) | 2020.06.27 |

