
BigQuery란?
- 엄청나게 큰 데이터에 대한 SQL 쿼리를 빠르게 수행해주는 google cloud platform의 서비스 중 하나
- 페타데이터(2^50TB, 데이터센터용 케비넷을 2개 채운느낌)에 달하는 데이터도 빠르게 분석 가능
- 자체 클러스터 구축 및 운영 필요 없는게 장점
Hadoop을 직접 구축한다면??...
- 데이터 분석에만 집중할 수 있어 많은 기업들에서 데이터웨어하우스로 많이 도입
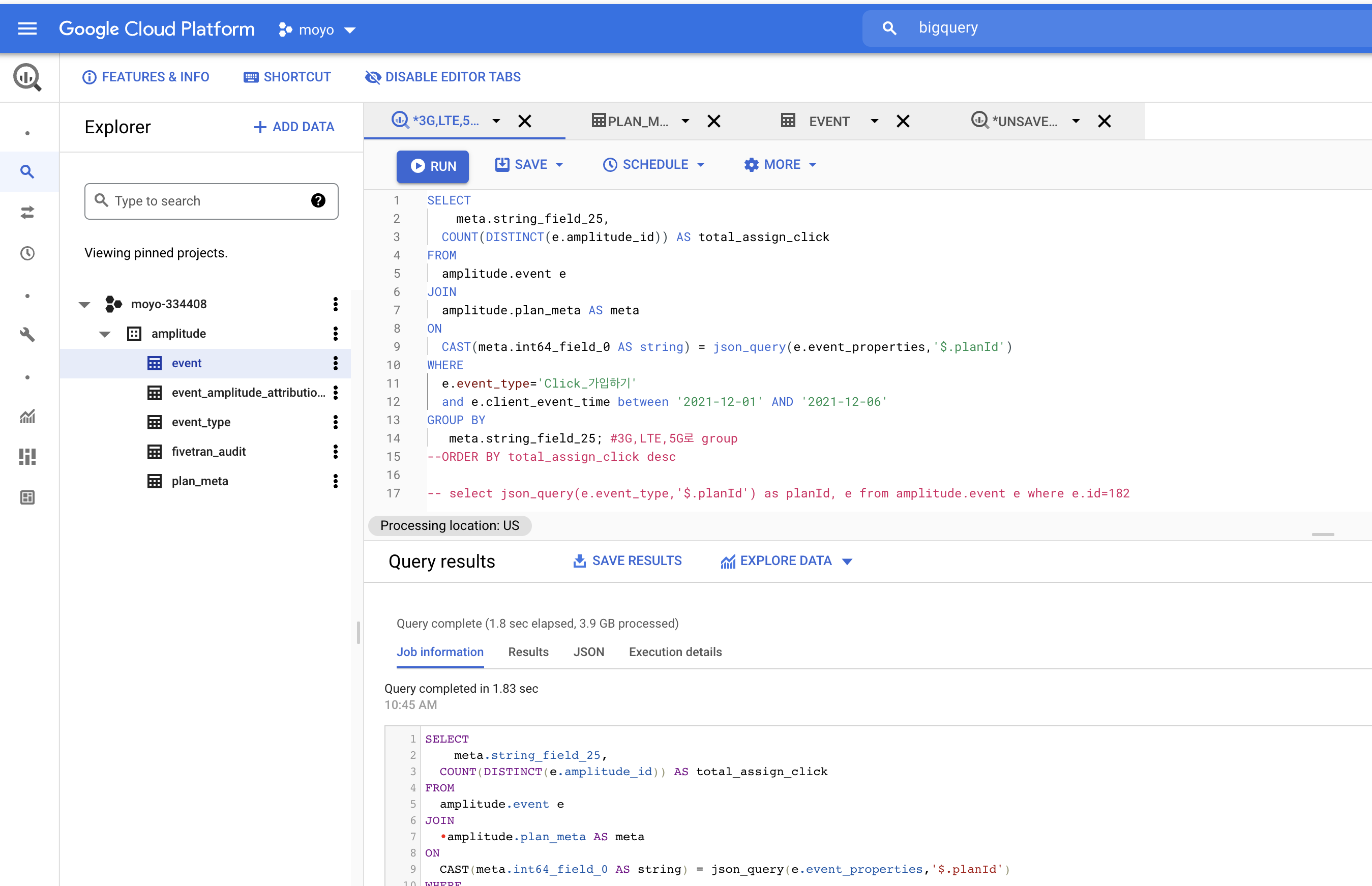
아래 화면은 빅쿼리 실행 세부정보를 보여주는 화면이다.
- 실행시간(Elapsed time) : 1.8초
- 처리한 데이터량 : 3.9GB
- 슬롯시간(Slot time consumed) : 32.9초
- 슬롯이란? 빅 쿼리가 분산처리를 하는 단위

도대체 BigQuery가 빠른 이유가 무엇인가?
Columnar Storage
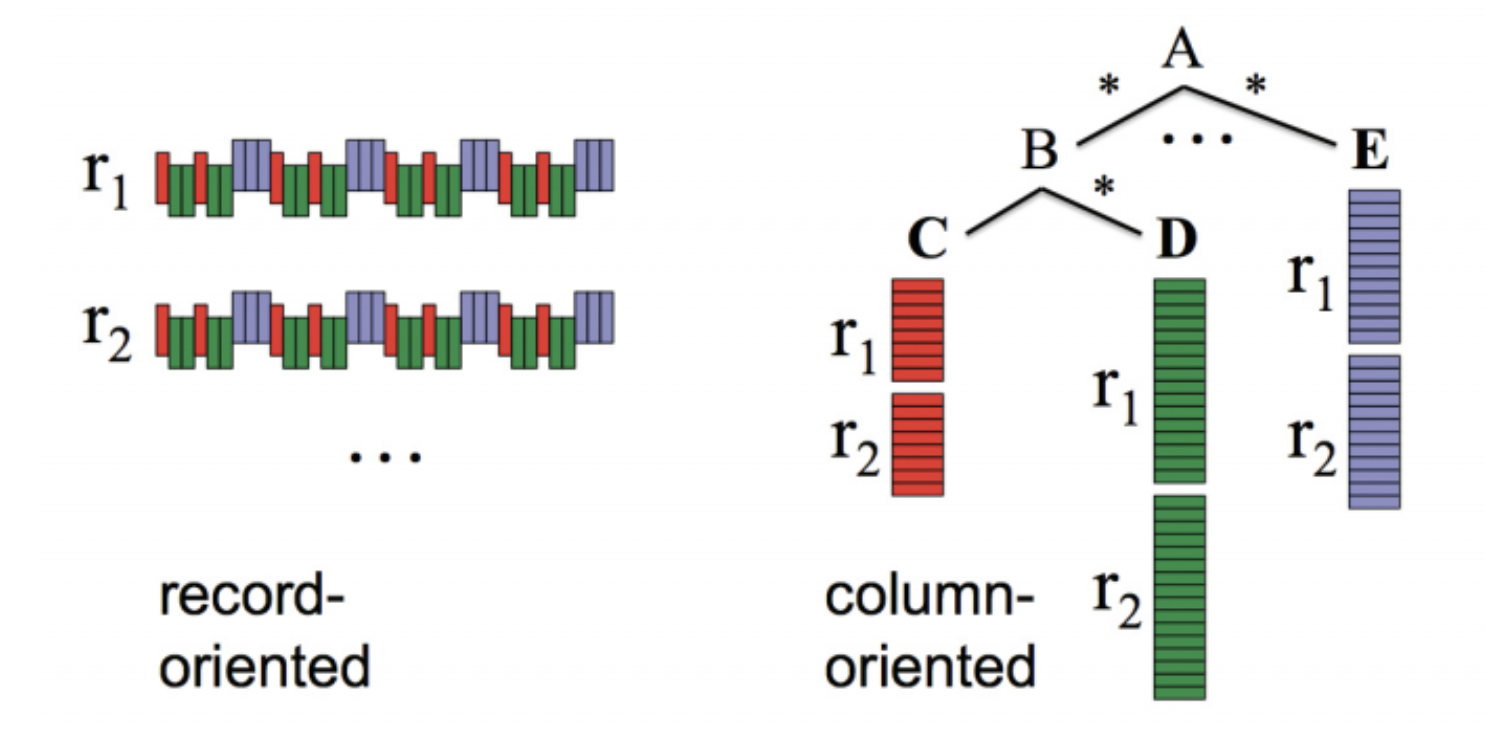
RDBMS는 레코드 단위로 데이터를 저장함 / 빅쿼리는 컬럼 단위로 데이터를 뜯어내어 저장함
1. 트래픽 최소화
SELECT TOP(amount) from order위와 같은 쿼리를 실행할 때 RDBMS는 레코드 단위로 전체를 조회하지만, 빅쿼리는 컬럼 기반 저장방식이기 때문에 해당 컬럼(amount)만 조회하면 된다.
2. 높은 압축 비율 ( Higher Compression Ratio )
컬럼 단위로 저장한다는 것은 같은 타입의 데이터들이 몰려서 저장된다. 그 결과, RDBMS는 1:3 비율로 압축하지만 컬럼 기반 저장은 1:10 비율로 압축이 가능합니다. 많이 압축한만큼 쿼리 수행 능력도 뛰어납니다.
이러한 컬럼 기반 저장은 RDBMS도 구현되어 있으며, Cassandra와 같이 column based nosql 솔루션들도 이미 존재한다.
하지만 빅쿼리는 대규모 분산 처리 능력 덕분에 성능을 극대화 시켜주었다.
3. 트리 기반의 분산처리
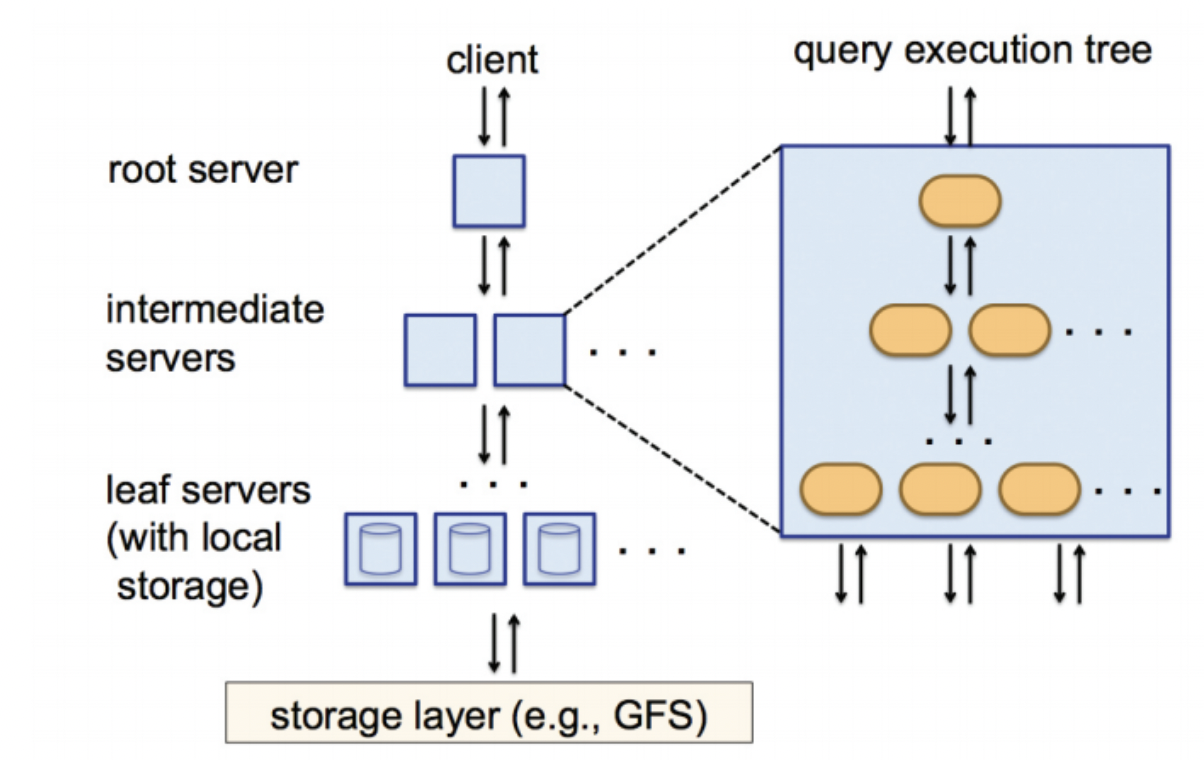
root server
- 클라이언트의 쿼리를 분석하여 분산 머신에서 동작하는 수많은 작은 단위의 쿼리문을 만들어줌
- 그 작은 쿼리를 intermediate servers에 전달
intermediate servers
- 실제 연산을 수행하는 leaf servers에게 쿼리를 전달
- 쿼리의 결과 값으로 반환되는 값들을 합쳐 root server에게 전달
leaf servers
- 실제 쿼리가 동작한는 곳
'데이터' 카테고리의 다른 글
| 데이터 중심 어플리케이션 설계 7장-트랜잭션 (0) | 2023.05.21 |
|---|---|
| 7장. 트랜잭션 ( 데이터 중심 애플리케이션 설계 ) (0) | 2020.06.27 |
| 1장. 신뢰할 수 있고 확장 가능하며 유지보수하기 쉬운 애플리케이션 [데이터중심 어플리케이션 설계] (0) | 2020.04.30 |

